Mono-repo or poly-repo
When we were starting a project from scratch, we were trying to figure out if we should go with a mono-repo or split it up and go with poly-repos. I wrote a page on my notion and jotted things down.
This article is that notion page, but edited to suit better to a blog.
Initial Suggestion
My initial suggestion was to use mono-repo, as it is the suggested method of code organisation to go along with trunk-based development and CI/CD workflow.
Why follow the industry practice?
I was inclined towards a mono-repo because frankly, it’s what I’ve seen the industry suggest. It wouldn’t always mean that it’s the best thing, but following the industry practices does one thing for us:
We won’t spend time finding bottlenecks, and issues during our development, which we would’ve otherwise had to work around.
When we follow the practices being used in the industry, we unknowingly navigate around potential problems, because the industry has already seen those and hence came up with industry practices.
The industry has been around longer than we have, and it consists of multiple individuals, their time testing out methodologies is far longer than our limited personal experiences.
But, that is not to say that we shouldn’t challenge these decisions. We should. But this means coming up with something better than what the industry already has presented. (Starting to sound like Dave Farley, pretty sure I’m using most of his ideas in this article :D )
If our alternatives offer extra features, but they don’t provide existing features that industry practices provide, then that alternative isn’t any better, or at least we shouldn’t call it an alternative but a whole new method.
If those features are really that good for software development, the industry would rush to use them.
Mono-repo and micro-services
We were planning to use micro-services, or to be generic, Distributed Services Architecture.
Let’s go over the points that have to be valid to call our services, microservices:
- Loosely coupled
- Independently deployable
- Autonomous
- Aligned with a bounded context
- Focused on a single task
- Small
The main arguments provided to me about avoiding mono-repos is because they encourage tight-coupling. That isn’t true.
The difference between mono-repo and multi-repo is how services are organised. A mono-repo stores all services in a single folder, yet each service lives in it’s own folder. Each folder represents a service. They aren’t totally dependent on other services.
A multi-repo has a repo for each service. The reason for this thought is because we have wired ourselves to think that a repo represents a single product. However, it’s just an organisational strategy.
Multi-repo structure
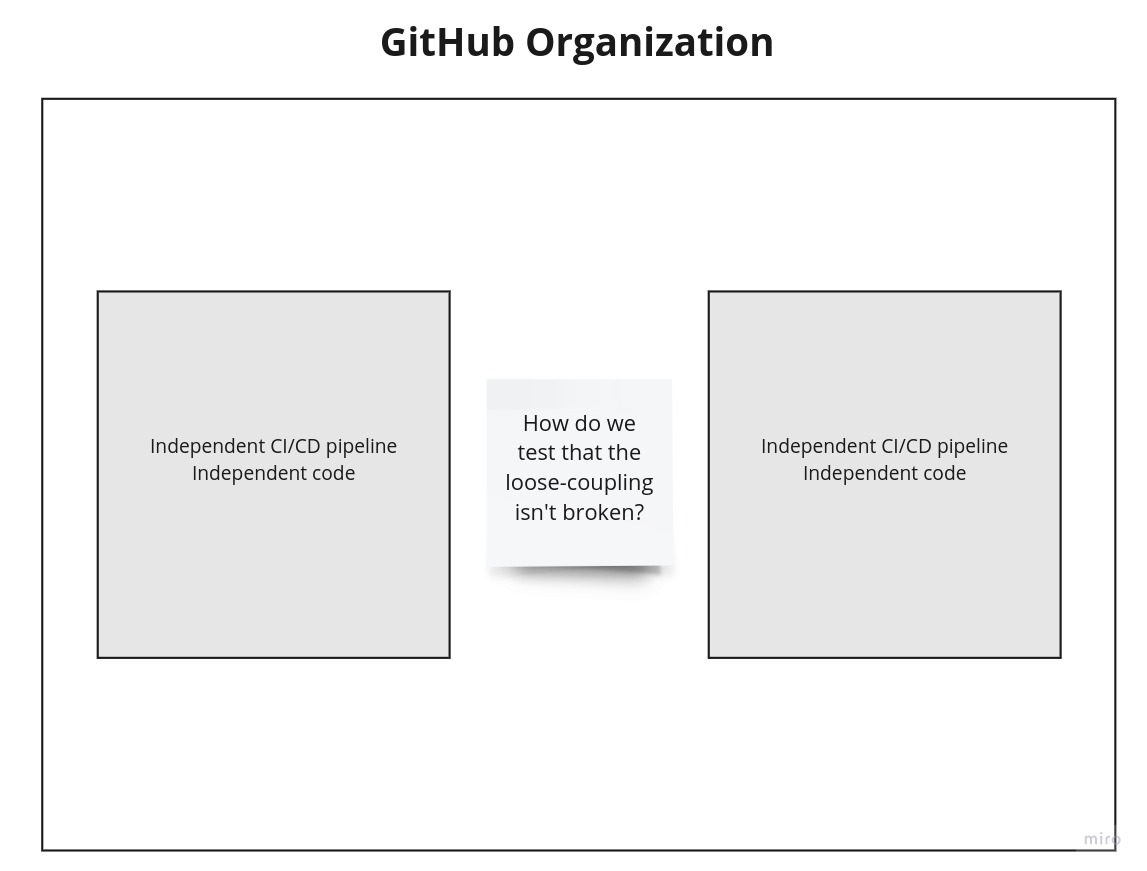
Let’s go a little deeper into this structure.
Both services are independent, represented by their own repo. An independent CI/CD pipeline is present in each repo.
We write automated tests to test each service on it’s own, but take a step back. How do these services communicate?
They are loosely-coupled. They are independently deployable, but they are still coupled to an extent.
If we deploy a service independently, how do we ensure that the newly deployed service will work with other services, and that its messaging isn’t broken?
Editor note: The way I’ve seen multi-repo projects handle CI/CD between multiple repos is, you guessed it, a whole new repo that contains pipelines to test out all other services. Don’t you think that this splits up shared knowledge across way too many repos?
Method A
We could write a test that tests the service request and response matches the one expected by other services. But with this, there’s a chance of discrepancy.
We have to write tests for both services that match the request/response expected from other services. It needs to be defined more than once, spanning over repos, and introducing the risk that the request/response structure can go out-of-sync
Let’s take a look at an example.
We have two microservices:
- Service A
- Service B
Both services are independently deployable and they’re loosely-coupled. Let’s see how they communicate:
Service A ⇒ Service B
Test Case #1: Sending Request to Service B Structure
{
"id": UUID
}Test Case #2: Receive Response from Service B Structure
{
"name": string
}How do we ensure both services know the request/response structure? We write automated tests.
Test Case for Service A (Request Only)
Test Case #1: Sending Request to Service B Structure
{
"id": UUID
}This test would ensure that our changes don’t break the format of the request. Now we have to do the same for Service B
Test Case for Service B (Request Only)
Test Case #2: Receive Request from Service A Structure
{
"id": UUID
}Can you find where the discrepancy can creep in?
First, we can see there is some redundant tests on both services. Service A tests that the request it sends follows a structure, and Service B tests that the request it receives follows a structure.
Request from Service A ⇒ Request to Service B
The request sent, and the service that receives it, both have to ensure that the structure is the same.
Let’s simplify this. We can have the request structure exist on it’s own.
Request A
{
"id": UUID
}Now Service A and Service B can both import this structure and write their own tests like so:
Service A
Test Case #1: Sending Request Structure
Send <Request A>Service B
Test Case #1: Receiving Request Structure
Receive <Request A>Any change in either Service A and Service B that changes the request, will cause the test to fail.
If we add a field in Service A, the test will fail until we add that field in Request A. This will cause the Service B test to fail, which will help us avoid shipping Service A, as Service B will be expecting the older Request A.
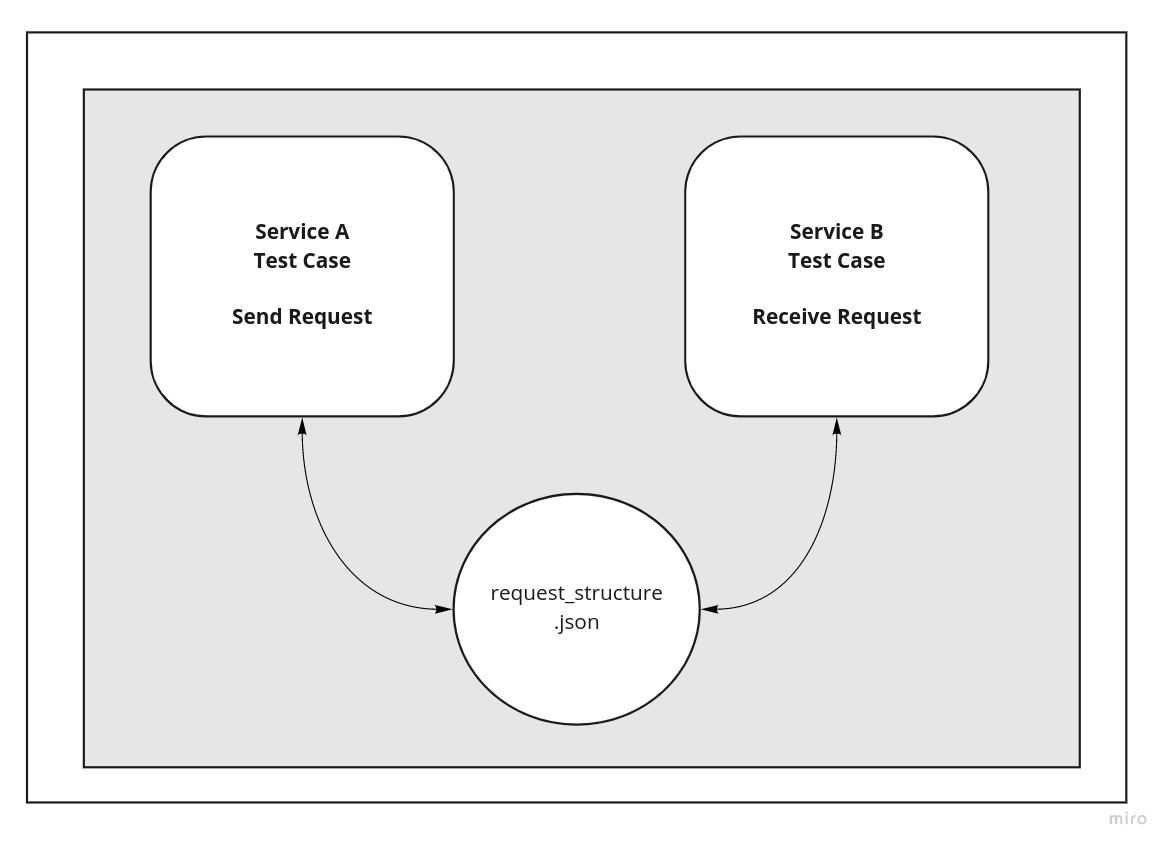
Editor note: This request_structure.json can be replaced with a much better alternative, OpenAPI Specification.
Testing this in a multi-repo environment is hard. We would have to define a shared structure between these two repos. This is mandatory because we want to test that the communication between microservices works, otherwise our services would be useless.
Mono-repo structure
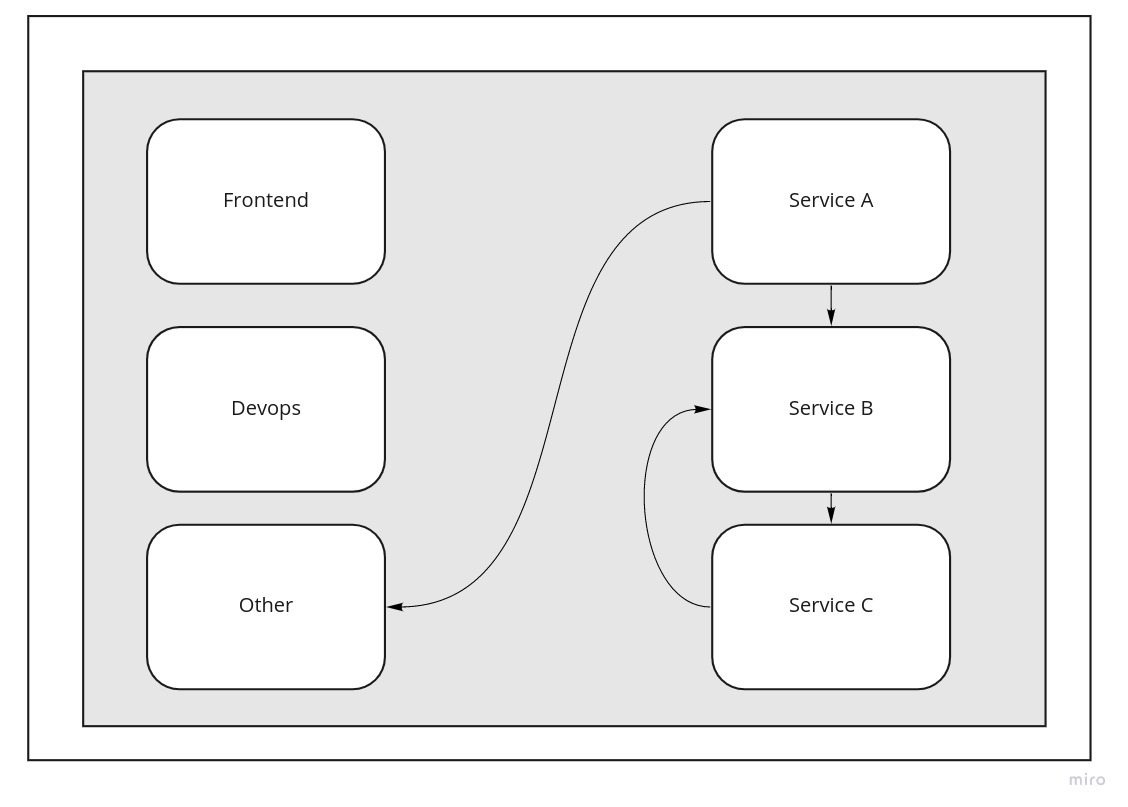 Mono-repo gives us the flexibility to define shared data in the repo, which can be used by all services in that repo.
Mono-repo gives us the flexibility to define shared data in the repo, which can be used by all services in that repo.
We cannot say the same about using multi-repo, as each repo contains one microservice, and it can only access the data that is present in that repo.
One way of using shared data in multi-repo is to use relative paths. But at that point, that’s exactly what a mono-repo helps accomplish.
Why bother with Poly-repo?
The biggest reason that is a fact: Git. Git starts getting slow with mono-repos, but it happens at the scale of really large companies (FAANG). Unless we’re one of them, us using mono-repo with Git is not going to be a problem.
Other than that, poly-repo would offer benefit if our number of engineers are at a high scale. If we’re talking about around 50-100 engineers, it doesn’t make sense to create separate repos and assign individuals to specific repos, because at that scale, no one would know how to deploy the whole system.
Below 3 paragraphs taken unedited from my notion page:
Why is this important? At our scale (think 2-3 years), the product is at a scale where an individual can at least know a bit about the whole system.
Code quality is directly related to communication. Segregating our team at the start, at this scale, is not a good decision.
Instead, combining the team as one and sharing ownership of the whole code-base is a better decision as each engineer will start becoming comfortable with the whole code-base.